- content {:toc}
基础应用
1 相关概念与快速开始
Git的安装与使用教程(超详细!!!)_9.冄2.7.號的博客-CSDN博客_git安装教程
版本控制是什么?
- 一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统
为什么需要版本控制?
- 更好的关注变更,了解到每个版本的改动是什么,方便对改动的代码进行检查,预防事故发生也能够随时切换到不同的版本,回滚误删误改的问题代码;
什么是 git
- Git 是一款免费、开源的分布式版本控制系统,他是著名的 Linux 发明者 Linus Torvalds 开发的
- GitHub 主要提供基于 git 的版本托管服务。也就是说现在 GitHub 上托管的所有项目代码都是基于 Git 来进行版本控制的,所以 Git 只是 GitHub 上用来管理项目的一个工具而已,GitHub 的功能可远不止于此!
1.1 GitHub 基本概念
Repository
- 仓库的意思,即你的项目,你想在 GitHub 上开源一个项目,那就必须要新建一个 Repository,如果你开源的项目多了,你就拥有了多个 Repositories 。
Issue
- 问题的意思,举个例子,就是你开源了一个项目,别人发现你的项目中有bug,或者哪些地方 做的不够好,他就可以给你提个 Issue ,即问题,提的问题多了,也就是 Issues ,然后你看 到了这些问题就可以去逐个修复,修复ok了就可以一个个的 Close 掉。
Star
- 这个好理解,就是给项目点赞,但是在 GitHub 上的点赞远比微博、知乎点赞难的多,如果你有一个项目获得100个star都算很不容易了!
Fork
- 这个不好翻译,如果实在要翻译我把他翻译成分叉,什么意思呢?你开源了一个项目,别人 想在你这个项目的基础上做些改进,然后应用到自己的项目中,这个时候他就可以 Fork 你的 项目,这个时候他的 GitHub 主页上就多了一个项目,只不过这个项目是基于你的项目基础 (本质上是在原有项目的基础上新建了一个分支,分支的概念后面会在讲解Git的时候说 到),他就可以随心所欲的去改进,但是丝毫不会影响原有项目的代码与结构。
Pull Request
- 发起请求,这个其实是基于 Fork 的,还是上面那个例子,如果别人在你基础上做了改进,后 来觉得改进的很不错,应该要把这些改进让更多的人收益,于是就想把自己的改进合并到原 有项目里,这个时候他就可以发起一个 Pull Request(简称PR) ,原有项目创建人就可以收 到这个请求,这个时候他会仔细review你的代码,并且测试觉得OK了,就会接受你的PR,这 个时候你做的改进原有项目就会拥有了。
Watch
- 这个也好理解就是观察,如果你 Watch 了某个项目,那么以后只要这个项目有任何更新,你 都会第一时间收到关于这个项目的通知提醒。
Gist
- 有些时候你没有项目可以开源,只是单纯的想分享一些代码片段,那这个时候 Gist 就派上用 场了!
1.2 git 目录结构
- Git 的本质是一个文件系统,工作目录中的所有文件的历史版本以及提交记录(commit)都是以文件对象的方式保存在
.git目录中的。 - git下的版本库只位于工作区根目录下的 git目录 , 仅此一处
- 目前的Key的类型四种,分别是dsa、rsa、ecdsa、ed25519, 默认使用的是rsa, 由于一些安全问题,现在已经不推荐使用dsa和rsa了,优先推荐使用ed25519
|
|
objects:这里是真正保存 Git 对象的目录,包括三类对象 commit,tree 和 blob- Blob存储文件的内容
- Tree存储文件的目录信息
- Commit存储提交信息,一个Commit可以对应唯一版本的代码
- refs 内容就是对应 Commit ID因此把ref当做指针, 指向对应的Commit来表示当前Ref对应的版本.
- Branch
git checkout -b可以创建一个新分支, 分支一般用于开发阶段,是可以不断添加 Commit 进行迭代的 - Tag标签一般表示的是一个稳定版本, 指向的Commit一般不会变更
- Branch
refs/head下保存 分支信息
1.3 密钥生成/ 设置用户名/ 缩写
|
|
1.3.pull &push/ 快速开始
|
|
1,5 git 的三种状态
Git 有三种状态,你的文件可能处于其中之一: 已提交(committed)、已修改(modified) 和 已暂存(staged)。
- 已修改表示修改了文件,但还没保存到数据库中。
- 已暂存表示对一个已修改文件的当前版本做了标记,使之包含在下次提交的快照中。
- 已提交表示数据已经安全地保存在本地数据库中。
1.6 objects
如何将三个信息串联在一起
- 通过
commit找到tree的信息, 每个 commit 都存储对应的tree id - 通过 tree 存储的信息, 获取对应的目录树结构
- 从
tree中 获取blob的id, 通过blob id获取对应的文件内容
2 远端仓库/ remote
2.1 http 和 git 协议有什么区别
- 第一组使用 HTTPS 协议,第二组使用 SSH 协议。具体选择哪种协议取决于你的需求和配置。
- 使用 HTTPS 协议需要提供用户名和密码,而使用 SSH 协议则需要设置密钥对。
|
|
其中
fetch:git fetch命令用于从远程仓库获取最新的代码和提交历史,但不会自动合并或更新你的本地分支。它将远程仓库的内容下载到你的本地仓库,使你能够查看和比较远程分支与本地分支之间的差异。fetch操作不会修改你的本地分支,只会更新你的本地仓库。push:git push命令用于将你的本地分支的提交推送到远程仓库。它将你的本地分支的提交上传到远程仓库,并将远程仓库的相应分支更新为你的提交。push操作会修改远程仓库的内容。
2.2 链接远程仓库
|
|
1.4 我当前在 dev分支, 运行 git push main会发生什么
如果你当前在 dev 分支,并且运行 git push main 命令,Git 会尝试将当前分支的提交推送到名为 main 的远程分支。
然而,由于你当前在 dev 分支,而不是 main 分支,这个命令可能会失败。因为默认情况下,git push 命令会将当前分支的提交推送到与当前分支同名的远程分支。
如果你想要将 dev 分支的提交推送到远程的 main 分支,你可以使用以下命令:
|
|
这个命令将会将本地的 dev 分支的提交推送到名为 origin 的远程仓库的 main 分支。
git fetch origin dev:main是什么意思
git fetch origin dev:main 命令的含义是从名为 origin 的远程仓库获取 dev 分支的最新提交,并将其存储为本地的 main 分支。
这个命令的具体含义如下:
git fetch:从远程仓库获取最新的提交和分支信息。origin:远程仓库的名称,通常是你克隆或者关联的远程仓库的默认名称。dev:远程仓库的分支名称,你希望获取其最新提交。main:本地分支的名称,用于存储从远程仓库获取的dev分支的提交。
通过运行这个命令,Git 会从 origin 远程仓库获取 dev 分支的最新提交,并将其存储为本地的 main 分支。这样,你就可以在本地的 main 分支上查看和操作从远程仓库的 dev 分支获取的提交。
需要注意的是,这个命令会将远程 dev 分支的提交直接应用到本地的 main 分支,而不会创建新的合并提交。这种操作可能会覆盖本地 main 分支上的提交,所以请确保在运行这个命令之前,你的本地 main 分支没有重要的未提交的更改。
查看文件内容
git cat-file 是一个用于查看 Git 对象内容的命令。Git 中的对象是存储在仓库中的基本数据单元,包括提交(commit)、树(tree)、标签(tag)和文件内容(blob)等。
使用 git cat-file 命令,你可以通过指定对象的哈希值或引用来查看对象的内容。它的基本语法如下:
|
|
这个命令将会返回指定对象的类型。例如,git cat-file -t abc123 将会返回对象 abc123 的类型,比如 commit、tree、tag 或 blob。
|
|
这个命令将会返回指定对象的内容。例如,git cat-file -p abc123 将会返回对象 abc123 的内容,比如提交信息、文件内容等。
通过使用 git cat-file 命令,你可以查看 Git 仓库中的对象的详细信息,这对于调试和了解仓库的内部结构非常有用。
希望这个解释对你有帮助。如果你还有其他问题,请随时告诉我!
3 分支操作
3.1 本地操作分支
|
|
3.2 想拉取远程仓库的 dev 分支怎么做
要拉取远程仓库的 dev 分支,可以按照以下步骤进行操作:
|
|
- 使用 git fetch origin dev 命令从远程仓库拉取 dev 分支的最新代码。这将会将远程仓库的 dev 分支代码下载到你本地仓库,不会自动合并到你当前的分支。
- 使用 git checkout dev 命令切换到 dev 分支。如果本地还没有 dev 分支,可以使用 git checkout -b dev origin/dev 命令创建并切换到 dev 分支。
现在你已经成功拉取了远程仓库的 dev 分支,可以开始在本地与该分支进行开发和修改。记得在操作前先保存好本地的修改,以免冲突。
3.3 远程分支
- 远程分支没有新建指令, 直接 push 就好
|
|
当我们使用git clone 时, 克隆下了远端的仓库的哪个分支
当你使用 git clone 命令克隆远程仓库时,默认情况下会克隆远程仓库的主分支(通常是 master 分支或者 main 分支)。 如果你想要克隆远程仓库的特定分支,可以使用 --branch 参数指定分支名称。例如,要克隆远程仓库的 develop 分支,可以运行以下命令:
|
|
拉取远端其他分支
|
|
3.4 合并分支
- Git 保存的不是文件的变化或者差异,而是一系列不同时刻的 快照 。在进行提交操作时,Git 会保存一个提交对象(commit object)。
- Git 的分支,其实本质上仅仅是指向提交对象的可变指针。
- Git 又是怎么知道当前在哪一个分支上呢? 也很简单,它有一个名为 HEAD 的特殊指针。指向当前所在的本地分支(译注:将 HEAD 想象为当前分支的别名)。
- 由于 Git 的分支实质上仅是包含所指对象校验和(长度为 40 的 SHA-1 值字符串)的文件,所以它的创建和销毁都异常高效。
|
|
区别
- rebase 跟 merge 的区别你们可以理解成有两个书架,你需要把两个书架的书整理到一起去,
- 第一种做法是 merge ,比较粗鲁暴力,就直接腾出一块地方把另一个书架的书全部放进去,虽然暴力,但是这种做法你可以知道哪些书是来自另一个书架的;
- 第二种做法就是rebase ,他会把两个书架的书先进行比较,按照购书的时间来给他重新排序,然后重新放置好,这样做的好处就是合并之后的书架看起来很有逻辑,但是你很难清晰的知道哪些书来自哪个书架的。
3.5 遇到冲突时的分支合并
- 有时候合并操作不会如此顺利。 如果你在两个不同的分支中,对同一个文件的同一个部分进行了不同的修改,Git 就没法干净的合并它们。
- 此时 Git 做了合并,但是没有自动地创建一个新的合并提交。 Git 会暂停下来,等待你去解决合并产生的冲突。
|
|
任何因包含合并冲突而有待解决的文件,都会以未合并状态标识出来。 Git 会在有冲突的文件中加入标准的冲突 解决标记,这样你可以打开这些包含冲突的文件然后手动解决冲突。 出现冲突的文件会包含一些特殊区段,看 起来像下面这个样子:
|
|
为了解决冲突,你必须选择使用由 ======= 分割的两部分中的一个,或者你也可以自行合并这些内
容。同时 <<<<<<< , ======= , 和 >>>>>>> 这些行被完全删除了。
3.6 多人合作冲突
远程跟踪分支是远程分支状态的引用。它们是你无法移动的本地引用。一旦你进行了网络通信, Git 就会为你移 动它们以精确反映远程仓库的状态。它们以<remote>/<branch> 的形式命名。
假设你的网络里有一个在 git.ourcompany.com 的 Git 服务器。 如果你从这里克隆,Git 的 clone 命令会为你自动将其命名为 origin,拉取它的所有数据, 创建一个指向它的 master 分支的指针,并且在本地将其命名为 origin/master。Git 也会给你一个与 origin 的master 分支在指向同一个地方的本地 master 分支,这样你就有工作的基础。
隔离性
- 如果你在本地的 master 分支做了一些工作,在同一段时间内有其他人推送提交到
git.ourcompany.com并且更新了它的 master 分支,这就是说你们的提交历史已走向不同的方向。 即便这样,只要你保持不与origin 服务器连接(并拉取数据),你的 origin/master 指针就不会移动。 - 如果要与给定的远程仓库同步数据,运行
git fetch <remote>命令
3.7 删除记录但保留代码
背景
- 以前开发中未制定、遵循 git 管理项目标准,随意 (不规范) 的提交 严重 “污染了” 提交历史,使开发主线 “脏乱”;
- 基于以前的仓库重新开发,这样可保留以前的配置等文件,但是需要删除全部的历史记录、tag、分支等;
- 由于自己或其他方面特殊需求,需要保留仓库的部分属性 (创建时间,说明,主页等),但需要清除历史记录,使其为 “新库”。
基于以上 3 方面的需求,需要提供一个 在不删除原仓库的前提下,清除原仓库的所有历史提交记录 (包含:分支、tag) 解决方案。
|
|
4 常见开发场景
1、本地仓库有文件,远程服务器上面是新建的仓库
|
|
2、远程服务器上面有很多代码,要拉取到本地开始开发
|
|
5 其他操作 / igonre
ignore
.gitignore 文件用于告诉 Git 哪些文件或目录应该被忽略,不纳入版本控制。当你在项目中创建一个 .gitignore 文件并列出要忽略的文件或模式时,Git 将不会跟踪或记录这些文件的更改。
.gitignore 文件的作用有以下几个方面:
- 忽略生成的文件:在开发过程中,你可能会生成一些临时文件、日志文件、编译输出文件等。通过在
.gitignore文件中列出这些文件的模式,你可以告诉 Git 忽略它们,避免将它们纳入版本控制。 - 忽略敏感信息:有时,你可能会在项目中包含一些敏感信息,如密码、API 密钥等。通过将这些敏感文件的路径添加到
.gitignore文件中,你可以确保它们不会被意外地提交到版本库中。 - 忽略操作系统和编辑器生成的文件:不同的操作系统和编辑器可能会生成一些特定的文件,如临时文件、缓存文件、配置文件等。通过
.gitignore文件,你可以告诉 Git 忽略这些与特定环境相关的文件。
.gitignore 文件使用简单的模式匹配规则来指定要忽略的文件或目录。你可以使用通配符、路径模式和其他规则来匹配文件名或路径。
需要注意的是,.gitignore 文件只对尚未被 Git 跟踪的文件起作用。如果某个文件已经被 Git 跟踪并提交到版本库中,那么即使将其添加到 .gitignore 文件中,Git 仍然会继续跟踪该文件。
工作说明
.gitignore 是一个文本文件,其中的每一行代表一个模式,表示匹配规则,开发人员需要忽略的模式相关的模式都应该放到.gitignore 文件中
.gitignore 一般放在代码库的根目录下,这是官方推荐的做法。但是你也可以把它放置在代码库里边的任意目录下,代码库可以有多个.gitignore 文件,其中的匹配模式的路径是相对当前.gitignore 所在目录的。
git add . 会追踪 gitignore的对象么
git add . 命令会将当前目录下的所有文件和文件夹添加到 Git 的暂存区,但它不会追踪 .gitignore 文件中指定的被忽略的对象。
.gitignore 文件的作用是告诉 Git 忽略某些文件或目录,不将它们纳入版本控制。当你运行 git add . 命令时,Git 会将所有未被忽略的文件添加到暂存区,但被 .gitignore 文件指定的被忽略的文件不会被添加到暂存区。
这意味着,.gitignore 文件中指定的被忽略的文件或目录不会被 git add . 命令追踪或添加到暂存区。它们将保持未被跟踪的状态,不会被包含在提交中。
如果你想要确保被 .gitignore 文件指定的被忽略的文件不会被 git add . 命令添加到暂存区,你可以使用 git add --ignore-errors . 命令。这个命令会忽略被忽略的文件,并继续添加其他未被忽略的文件到暂存区。
需要注意的是,一旦某个文件被添加到暂存区并提交到版本库中,.gitignore 文件对该文件将不再起作用。如果你想要从版本库中移除已经提交的文件,你需要使用 git rm --cached <file> 命令。
希望这解答了你的问题!如果还有其他问题,请随时问我。我会尽力帮助你!
提交操作
|
|
日志操作
|
|
拉取操作概念辨析
Clone拉取完整的仓库到本地目录,可以指定分支,深度.Fetch将远端某些分支最新代码拉取到本地,不会执行merge操作,会修改refs/remote内的分支信息,如果需要和本地代码合并需要手动操作.Pull拉取远端某分支,并和本地代码进行合并,操作等同于 git fetch + git merge,也可以通过 git pull –rebase 完成 git fetch + git rebase 操作. 可能存在冲突,需要解决冲突.
|
|
高级应用
6 github action
Github Action 官方文档:https://docs.github.com/en/actions/reference/workflow-syntax-for-github-actions#name
是 Github 推出的持续集成工具
持续集成是什么?
简单说就是自动化的打包程序 —— 如果是前端程序员,这样解释比较顺畅:
每次提交代码到 Github 的仓库后,Github 都会自动创建一个虚拟机(Mac / Windows / Linux 任我们选),来执行一段或多段指令(由我们定),例如:
- npm install
- npm run build
Yaml 是什么?
我们集成 Github Action 的做法,就是在我们仓库的根目录下,创建一个 .github 文件夹,里面放一个 *.yaml 文件 —— 这个 Yaml 文件就是我们配置 Github Action 所用的文件。
它是一个非常容易地脚本语言,如果我们不会的话,也没啥大事继续往下看就成了。
参考文档:五分钟学习 YAML
Github Action 的使用限制
- 每个 Workflow 中的 job 最多可以执行 6 个小时
- 每个 Workflow 最多可以执行 72 小时
- 每个 Workflow 中的 job 最多可以排队 24 小时
- 在一个存储库的所有 Action 中,一个小时最多可以执行 1000 个 API 请求
- 并发工作数:Linux:20,Mac:5(专业版可以最多提高到 180 / 50)
什么是 Workflow?
Workflow 是由一个或多个 job 组成的可配置的自动化过程。我们通过创建 YAML 文件来创建 Workflow 配置。
一、如何定义 Workflow 的名字?
name
Workflow 的名称,Github 在存储库的 Action 页面上显示 Workflow 的名称。
如果我们省略 name,则 Github 会将其设置为相对于存储库根目录的工作流文件路径。
|
|
二、如何定义 Workflow 的触发器?
on
触发 Workflow 执行的 event 名称,比如:每当我提交代码到 Github 上的时候,或者是每当我打 TAG 的时候。
|
|
事件大全:https://docs.github.com/en/actions/reference/events-that-trigger-workflows#about-workflow-events
三、Workflow 的 job 是什么?
答:一个 Workflow 由一个或多个 jobs 构成,含义是一次持续集成的运行,可以完成多个任务。
1、如何定义一个 job?
|
|
答:通过 job 的 id 定义。
每个 job 必须具有一个 id 与之关联。
上面的 my_first_job 和 my_second_job 就是 job_id。
2、如何定义 job 的名称?
jobs.<job_id>.name
name 会显示在 Github 上
3、如何定义 job 的依赖?job 是否可以依赖于别的 job 的输出结果?
jobs.<job_id>.needs
答:needs 可以标识 job 是否依赖于别的 job—— 如果 job 失败,则会跳过所有需要该 job 的 job。
|
|
jobs.<jobs_id>.outputs:用于和 need 打配合,outputs 输出 =》need 输入
jobs 的输出,用于和 needs 打配合:可以看到 ouput
|
|
4、如何定义 job 的运行环境?
jobs.<job_id>.runs-on
指定运行 job 的运行环境,Github 上可用的运行器为:
- windows-2019
- ubuntu-20.04
- ubuntu-18.04
- ubuntu-16.04
- macos-10.15
|
|
5、如何给 job 定义环境变量?
jobs.<jobs_id>.env
|
|
6、如何使用 job 的条件控制语句?
jobs.<job_id>.if
我们可以使用 if 条件语句来组织 job 运行
四、Step 属性是什么?
答:每个 job 由多个 step 构成,它会从上至下依次执行。
step 运行的是什么?
step 可以运行:
- commands:命令行命令
- setup tasks:环境配置命令(比如安装个 Node 环境、安装个 Python 环境)
- action(in your repository, in public repository, in Docker registry):一段 action(Action 是什么我们后面再说)
每个 step 都在自己的运行器环境中运行,并且可以访问工作空间和文件系统。
因为每个 step 都在运行器环境中独立运行,所以 step 之间不会保留对环境变量的更改。
|
|
五、Action 是什么?
我们可以直接打开下面的 Action 市场来看看:
Action 其实就是命令,比如 Github 官方给了我们一些默认的命令:
比如最常用的,check-out 代码到 Workflow 工作区:
1、我们应该如何使用 Action?
jobs.<job_id>.steps.uses
比如我们可以 check-out 仓库中最新的代码到 Workflow 的工作区:
|
|
当然,我们还可以给它添加个名字:
|
|
再比如说,我们如果是 node 项目,我们可以安装 Node.js 与 NPM:
|
|
2、上面我们为什么要用:@v2 和 @v2-beta 呢?
答:首先,正如大家所想,这个 @v2 和 @v2-beta 的意思都是 Action 的版本。
我们如果不带版本号的话,其实就是默认使用最新版本的了。
但是 Github 官方强烈要求我们带上版本号 —— 这样子的话,我们就不会出现:写好一个 Workflow,但是由于某个 Action 的作者一更新,我们的 Workflow 就崩了的问题。
3、上面的 with 参数是什么意思?
答:有的 Action 可能会需要我们传入一些特定的值:比如上面的 node 版本啊之类的,这些需要我们传入的参数由 with 关键字来引入。
具体的 Action 需要传入哪些参数,还请去 Github Action Market 中 Action 的页面中查看。
具体库的使用和参数,我们可以去官方的 Action 市场查看:
六、我们如何运行命令行命令?
上文说到,steps 可以运行:action 和 command-line programs。
我们现在已经知道可以使用 uses 来运行 action 了,那么我们该如何运行 command-line programs 呢?
答案是:run
run 命令在默认状态下会启动一个没有登录的 shell 来作为命令输入器。
1、如何运行多行命令?
每个 run 命令都会启动一个新的 shell,所以我们执行多行连续命令的时候需要写在同一个 run 下:
- 单行命令
|
|
- 多行命令
|
|
2、如何指定 command 运行的位置?
使用 working-directory 关键字,我们可以指定 command 的运行位置:
|
|
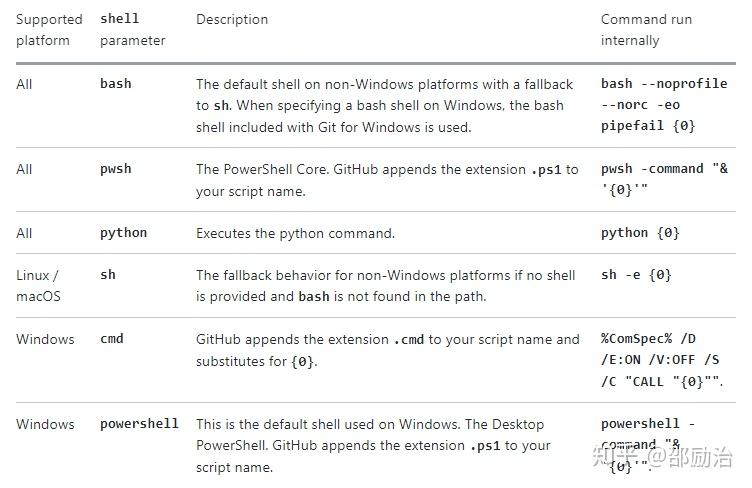
3、如何指定 shell 的类型?(使用 cmd or powershell or python??)
使用 shell 关键字,来指定特定的 shell:
|
|
下面是各个系统支持的 shell 类型:
七、什么是矩阵?
答:就是有时候,我们的代码可能编译环境有多个。比如 electron 的程序,我们需要在 macos 上编译 dmg 压缩包,在 windows 上编译 exe 可执行文件。
这种时候,我们使用矩阵就可以啦~
比如下面的代码,我们使用了矩阵指定了:2 个操作系统,3 个 node 版本。
这时候下面这段代码就会执行 6 次 —— 2 x 3 = 6!!!
|
|
下一篇文章:《实战:electron 通过 Github Action 自动打包,并上传到 Github 的 release 中》
敬请期待!!!!!
2 github 妙用
1.3 建立图片存储仓库
建立 public 仓库
设置 -> 开发者设置 -> 个人访问令牌-> 生成新令牌-> 设置有效期
申请的Token只会显示一次,当你第二次在打开该页面时就无法看到该Token了。如果忘记了Token,唯一的办法就是重新生成一个
注意如果上传的文件和仓库里的文件重名,会上传失败
|
|
工作流
| 分支管理工作流 | 特点特点特点 |
|---|---|
| Git Flow | 分支类型丰富,规范严格 |
| Github Flow | 只有主干分支和开发分支,规则简单 |
| Gitlab Flow | 在主干分支和开发分支之上构建环境分支,版本分支,满足不同发布or环境的需要 |
1. git flow
包含五种类型的分支
-
Master: 主干分支
-
Develop: 开发分支
-
Feature: 特性分支
-
Release: 发布分支
-
Hotfix: 热修复分支
优点
- 如果能按照定义的标准严格执行代码会很清晰,并且很难出现混乱.
缺点
- 流程过于复杂,上线的节奏会比较慢. 由于太复杂,研发容易不按照标准执行从而导致代码出现混乱.
github flow
Github 的工作流,只有一个主干分支,基于 Pull Request 往主干分支中提交代码.
选择团队合作的方式 ( 两种 )
- owner创建好仓库后, 其他用户通过 Fork的方式来创建自己的仓库, 并在 fork的仓库上进行开发
- owner 创建好仓库后, 统一给团队内成员分配权限, 直接在同一个仓库内进行开发
gitlab flow
- Gitlab推荐的工作流是在GitFlow和 Github Flow上做出优化,既保持了单一主分支的简便,又可以适应不同的开发环境
原则:
- upstream first 上游优先
- 只有在上游分支采纳的代码才可以进入到下游分支,一般上游分支就是
master
代码合并
Fast-Forward
不会产生一个merge节点,合并后保持一个线性历史,如果target分支有了更新,则需要通过 rebase操作更新 source branch 后才可以入.
Three-Way Merge
三方合并,会产生一个新的 merge节点
如何选择合适的工作流
选择原则: 没有最好的,只有最合适的
针对小型团队合作, 推荐使用Github工作流即可
- 1.尽量保证少量多次,最好不要一次性提交上千行代码
- 提交 Pull Request 后最少需要保证有 CR 后再合入
- 主干分支尽量保持整洁,使用 fast-forward 合入方式,合入前进行
rebase
一次混乱的开发流程
昨天看了下分支,好像大家拉的比较乱,
- dev是完成 dao 层以后的,
- user是 dev 加了用户登录,
- token 是 dev 加了 token功能
- feed是 user 加了 feed 功能,
- publish是在user上改的